From Dell:
As a clustered file system, PowerScale OneFS provides a mechanism to coordinate operations that happen on separate nodes. The OneFS Distributed Lock Manager (DLM) provides a cluster-wide coherent set of lock domains that allow the OneFS file system code on each node to coordinate operations and maintain file system integrity. Additionally, the lock manager provides a way for distributed software applications to synchronize their access to shared resources.
The DLM not only locks files; it coordinates all disk access. Multiple domains, advisory file locks (advlock), mirrored metadata operations (MDS locks), and logical inode number (LIN locks) for operations involving file system objects that have an inode—such as files or directories—exist within the lock manager. LIN locks constitute the majority of lock issues.
What are deadlocks?
When one or more processes have obtained locks on resources, a situation can occur in which each process prevents another from obtaining a lock, and none of the processes can proceed. This condition is known as a deadlock.
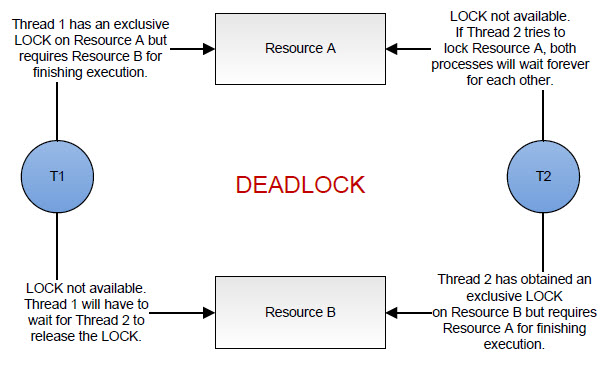
Any multi-process file system architecture that involves locking has the potential for deadlocks if any thread needs to acquire more than one lock at the same time. Developers have adopted two general approaches to handle this possibility:
Try to ensure the code cannot deadlock. This approach involves such mechanisms as consistently acquiring locks in the same order. It's generally challenging, not always practical, and can have ugly performance implications for the fast path code.
Accept that deadlocks occur and handle them.
OneFS takes the latter approach. That's not to say that we're cavalier about deadlocks. We do try very hard to ensure that deadlocks don't occur. But corner cases exist, and it's more efficient to just handle deadlocks by breaking the locks and trying to establish the locks again.
For additional details about deadlocks, see What is a deadlock, article 16674. For more information on how to recover from a potential cluster-wide deadlock, and how to gather useful data for diagnostic purposes, see How to recover from a cluster-wide deadlock, article 16688 on the Dell EMC Online Support site.
What are hangdumps?
A hangdump is an event on the cluster where a collection of log files is generated by isi_hangdump_d when the cluster detects a "hang" condition due to merge lock timeouts and deadlocks. The collection of these files are called hangdumps. Hangdumps usually trigger automatically, but they may be manually triggered if desired.
Hangdumps and lock contention
OneFS monitors each lock domain and has a built-in soft timeout—the amount of time in which we generally expect a lock request to be satisfied—associated with it. If a thread holding a lock blocks another thread's attempt to obtain a conflicting lock type for longer than the soft timeout, a hangdump is triggered to collect a large amount of diagnostic information in case an underlying issue exists. A hangdump is a dump of the system state, including the state of every lock in every domain, plus the stack traces of every thread on every node in the system.
When a thread is blocked for an extended period of time, any client that is waiting for the work that the thread is performing is also blocked. The external symptoms that may or may not be observed include:
Open applications stop taking input but do not shut down.
Open windows or dialogues cannot be closed.
The system cannot be restarted normally because it does not respond to commands.
A node does not respond to client requests.
Hangdumps can occur due to:
A temporary situation: The time to obtain the lock was long enough to trigger a hangdump, but the lock is eventually granted. This is the less serious situation. The symptoms are general slowness of the cluster, but the cluster is still able to make forward progress. Causes could include excessive workload for the cluster size, and corner cases in which the OneFS design does not perform optimally. (There is a potential for improvement in the latter case.)
A persistent situation: The problem won't go away without significant remedial action, such as node reboots. This is usually indicative of a bug in OneFS, although it could also be caused by hardware issues, where hardware becomes unresponsive, and OneFS waits indefinitely for it to recover.
A hangdump is not necessarily a serious problem. Certain normal operations, especially on very large files, have the potential to trigger a hangdump with no long-term ill effects. However, in some situations the waiter—the thread or process that is waiting for the lock to be freed—never gets the lock on the file. In that case, users may be impacted.
If you see a hangdump, and it's a LIN lock timeout (the most likely scenario), this means that at least one thread in the system has been waiting for a LIN lock for over 90 seconds. The system hang might be due to just one thread, or it might be due to more. It might be blocking a batch job. The system hang could be affecting an interactive session, in which case, users will likely notice performance impacts on the cluster.
Specifically, in the case of a LIN lock timeout, if you have the LIN number, you can easily map that back to a filename using the isi get -L <lin #> command, although if the LIN is still locked, you might have to wait until the LIN is no longer locked to get the name of the file.
Can I use OneFS log files to understand hangdumps?
The hangdump files in the /var/crash directory are compressed text files that you can examine. PowerScale OneFS has internal tools to analyze the logs from all of the nodes and generate a graph to show the lock interactions between the holders—the thread or process that is holding the file—and waiters. The analytics are by-node and include a full dump of the lock state as seen by the local node, a dump of every stack of every thread in the system, and various other diagnostics, for example, memory usage. However, these tools are not shipped with OneFS because storage administrators cannot easily use the output. Generally, you need OneFS source-code access to get value from the stack traces. Contact Dell EMC Online Support to investigate the hangdump log file data. You can then use that data to drive further investigation.
Here's what can be done:
Ensure that the cluster isn't impacted:
Code: Select all
for i in `isi_nodes %{lnn}`; do echo "Node" $i; isi_for_array -Qn$i sysctl efs.lin.lock.initiator.active_entries | awk '/ resource = 0 /{p=1;print;next}p&&/ resource = .:.*/{p=0};p' | awk '/type = exclusive/{p=1;print;next}p&&/^ }/{p=0};p' |egrep -A5 -B 50 'bam_event_oprestart|bam_rename' ; done
Node 1
Node 2
Node 3
Node 4
Node 5
Node 6
Node 7
Node 8
Node 9
Node 10
Node 11
Node 12
Node 13
Node 14
Node 15
Node 16
Node 17
Node 18
(if you see fewer nodes that's OK)
Execute command:
isi_sysctl_cluster efs.bam.rename_event_coherency=0
Ensure that the cluster isn't impacted:
Code: Select all
for i in `isi_nodes %{lnn}`; do echo "Node" $i; isi_for_array -Qn$i sysctl efs.lin.lock.initiator.active_entries | awk '/ resource = 0 /{p=1;print;next}p&&/ resource = .:.*/{p=0};p' | awk '/type = exclusive/{p=1;print;next}p&&/^ }/{p=0};p' |egrep -A5 -B 50 'bam_event_oprestart|bam_rename' ; done
Node 1
Node 2
Node 3
Node 4
Node 5
Node 6
Node 7
Node 8
Node 9
Node 10
Node 11
Node 12
Node 13
Node 14
Node 15
Node 16
Node 17
Node 18
(if you see fewer nodes that's OK)
Execute:
isi_sysctl_cluster efs.bam.rename_event_coherency
Should read this:
efs.bam.rename_event_coherency=0